Concept: Correspondence Analysis
Core Intuition
Correspondence Analysis (CA) is a dimensionality reduction and data visualization technique for contingency tables of counts. It reveals associations between row and column categories by mapping them into a shared low-dimensional space, where proximity indicates similarity of profiles.
Three key properties:
- Aggregate data based: operates on summarized count tables, not raw observations.
- Dimension reduction: represents associations in a table of nonnegative counts.
- Data visualization for association: positions of points reflect category associations.
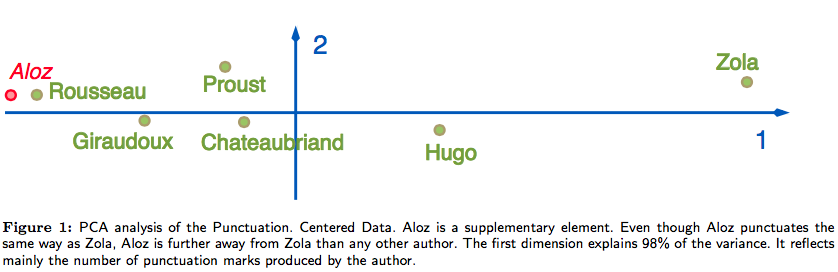
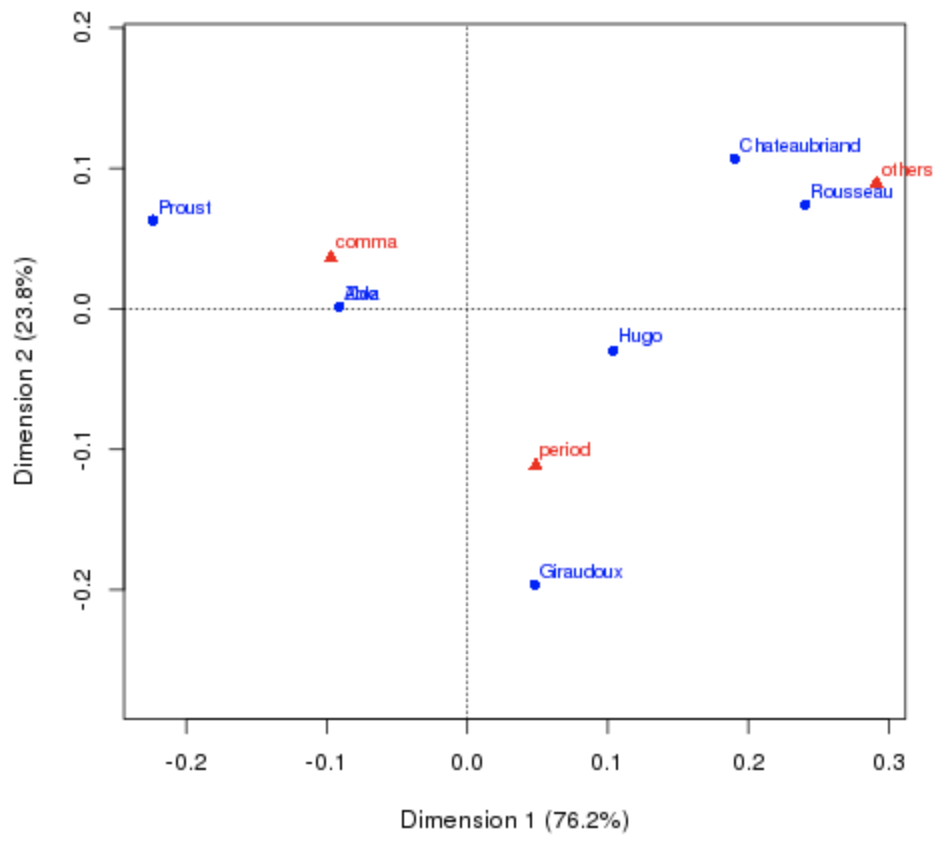
Why not PCA? PCA is sensitive to the magnitude of counts, not their relative profiles. In the French authors dataset (punctuation style by author), PCA places Aloz far from Zola despite identical punctuation style — because Aloz wrote a short novel. CA normalizes by profile, correctly grouping Aloz and Zola together.
Example applications
- Segments vs. genders / hours / weekdays / locations / app detection
- Segments vs. {only-impressions, with-clicks, with-actions}
- Campaigns vs. {only-impressions, with-clicks, with-actions}
- Other groups vs. characteristics, etc.
Archaeological example: sites vs. types
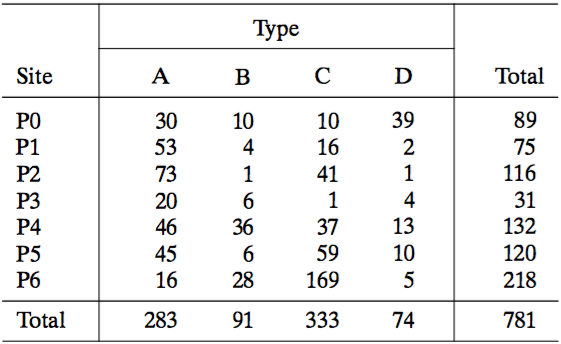
Common bar charts cannot quantify associations:

CA visualization:
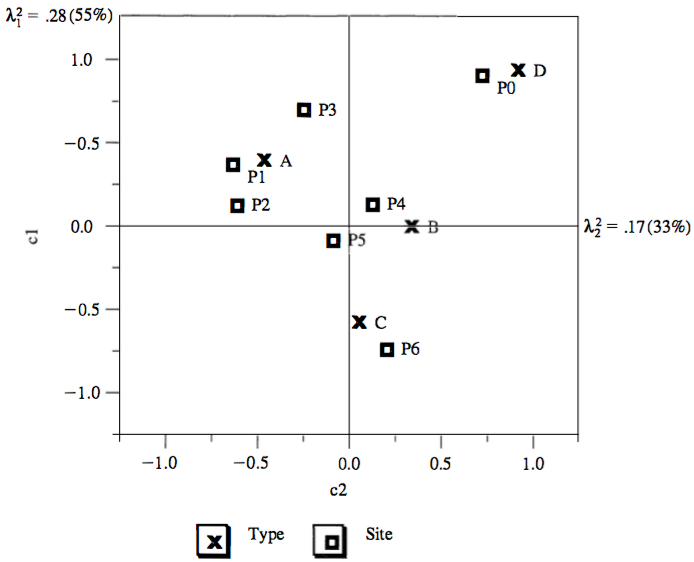
- Sites association:
- P1 and P2 are close together, thus have similar type profiles
- P0 and P6 are far apart, thus have different type profiles
- Types association:
- A, B, C and D have different site profiles
- Site and type association: (rough, see later)
- Site P0 is associated almost exclusively with type D
- Site P6 is similarly associated with type C
- Sites P1, P2 and P3 (to lesser degrees) are associated with type A
- Measure of retained information:
- Inertia: amount of retained information with
- 1st dimension:
- 2nd dimension:
- The two dimensions account for of the total inertia
- The representation fits the data well
- Inertia: amount of retained information with
Mathematical Foundation
CA is based on generalized singular value decomposition (SVD), similar to PCA, except it applies to categorical rather than continuous data.
Setup
Let the observed data be a contingency table of unscaled counts:
The rows and columns of correspond to different categories (groups) of different characteristics.
Correspondence Matrix and Profiles
Correspondence matrix: divide by total count :
Row and column marginal profiles:
Diagonal weight matrices:
Weighted Least Squares Formulation
CA finds a reduced rank- approximation minimizing:
Result from (Johnson & Wichern, 2002, p. 72): The term is common to the approximation whatever the correspondence matrix . Thus it is equivalent to minimize:
Generalized SVD
Compute the SVD of :
where and are orthogonal matrices with , and is a rank- diagonal matrix. Thus:
where and . This decomposition is called the generalized SVD:
Row and Column Profile Matrices
Row profile matrix (divide each row by its sum):
Column profile matrix (divide each column by its sum):
Row deviations from average row profile:
Column deviations from average column profile: similarly,
Principal and Standard Coordinates
Hence, we can obtain coordinates of the row and column profiles:
Principal coordinates of rows: the coordinates for w.r.t. the axes of are given by the columns of
Principal coordinates of columns: the coordinates for w.r.t. the axes of are given by the columns of
Standard coordinates of rows:
Standard coordinates of columns:
Relationships:
Inertia
Total variance of the correspondence matrix , resembling a chi-square statistic:
Evaluation of 2D graphical display:
- Inertia associated with dimension , for : .
- Proportion of total inertia: explained total variance; the larger, the better.
Visualization Maps
- (1) Symmetric map: , rows and columns in principal coordinates.
- (2) Asymmetric map with row principal: , rows (of more interest) in principal and columns in standard coordinates.
- (3) Asymmetric map with column principal: , rows in standard and columns (of more interest) in principal coordinates.
For interpretation details see (Greenacre, 2007, p. 66-72).
Symmetric map (1):
- Since principal coordinates are scaled similarly, joint display of two separate maps finds some justification.
- Thus, row-to-row and column-to-column distance interpretations are meaningful.
- However, there is a danger in row-to-column distance interpretation: not possible to deduce from the closeness of a row and column point that the corresponding row and column necessarily have a high association, since the row space and column space are different.
Asymmetric maps (2) and (3):
- The row and column points lie in the same space (since is with respect to basis , and ), thus not only row-to-row and column-to-column distance interpretations, but also row-to-column distance interpretation are meaningful.
- Closeness of a row and column point indicates a high association; row-to-column distances can be calculated one column at a time.
Interpretations:
- Asymmetric plots allow intuitively interpreting row-to-row, column-to-column, and row-to-column distances, especially when the first two components have a large proportion of total inertia.
- However, principal points on an asymmetric plot might appear too close to each other in the center of the map. In that case, also display a symmetric plot to more clearly view the relationships among either the row or column categories.
Example: Smoking dataset:
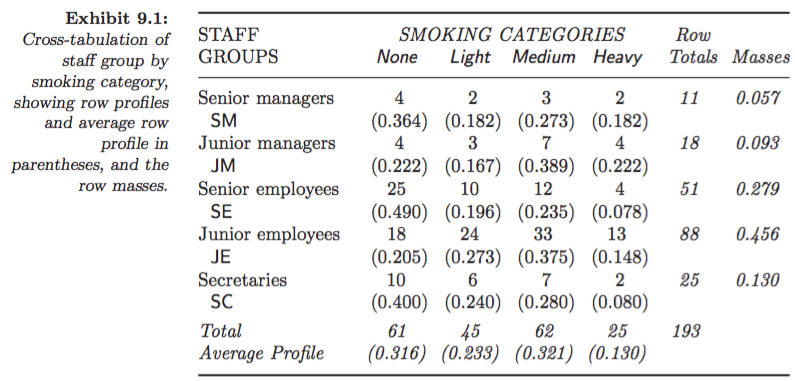
Asymmetric map, row principal (Greenacre 2007, Fig. 9.2):
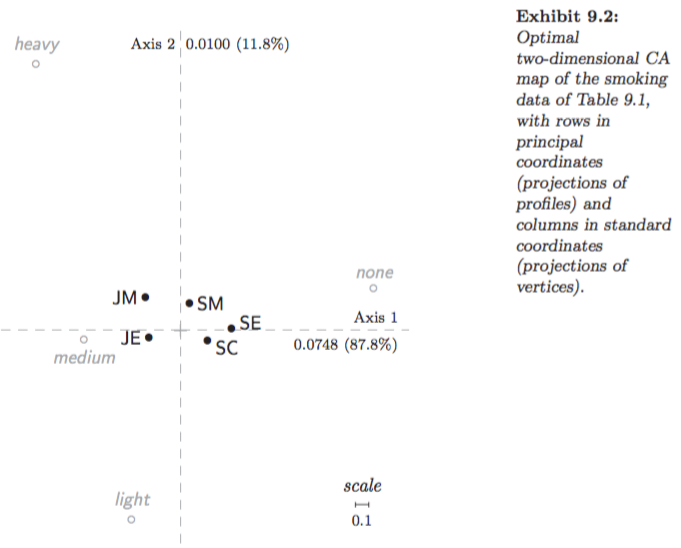
Asymmetric map, column principal (Greenacre 2007, Fig. 9.4):
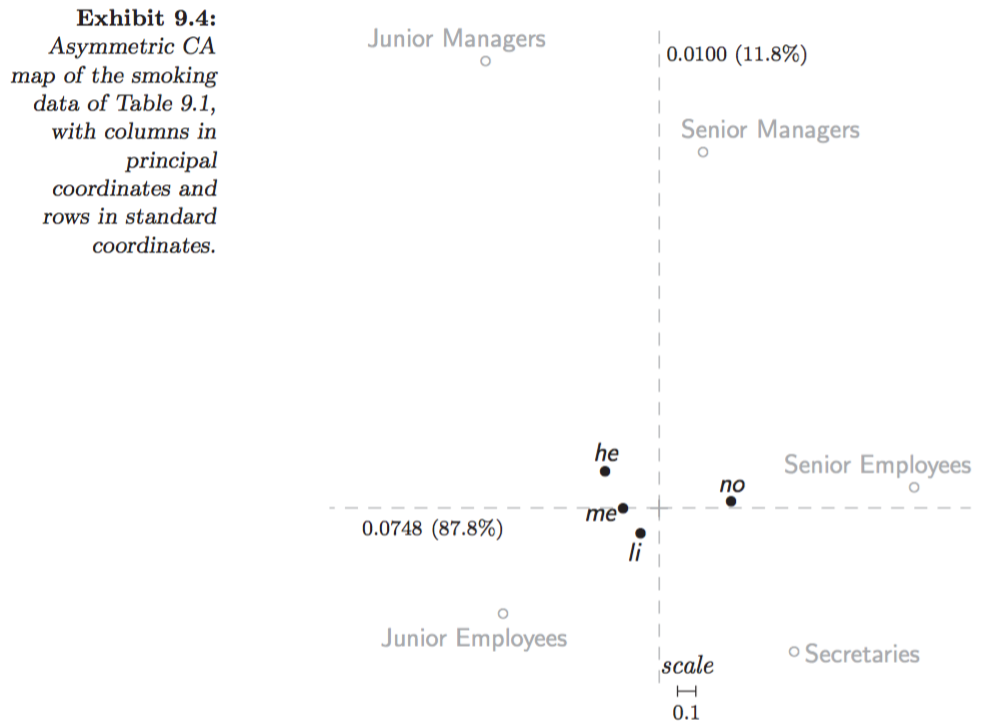
Symmetric map (Greenacre 2007, Fig. 9.5):
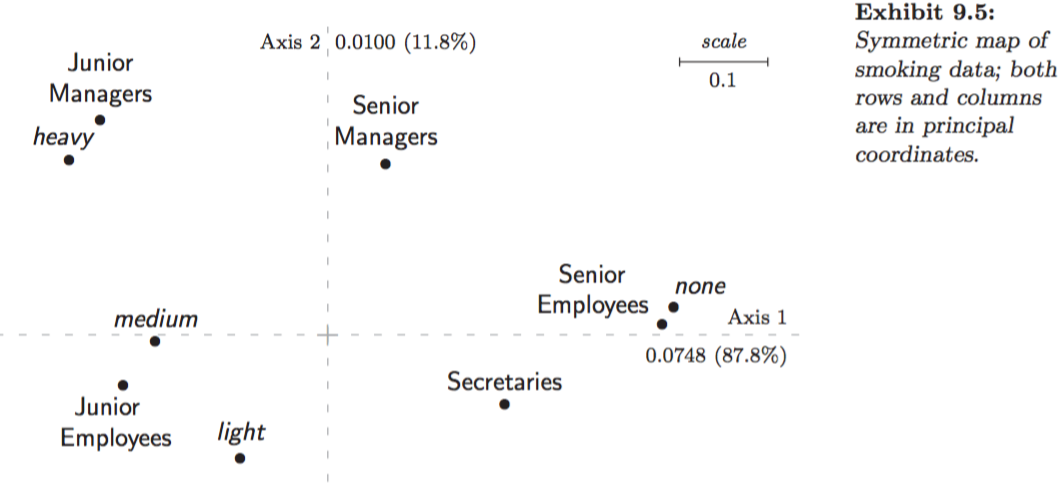
French Authors Dataset
Goal: derive a map that reveals the similarities in punctuation style between authors. Note: Zola wrote a short novel under the pseudonym Aloz.
import numpy as np
import scipy as sp
import pandas as pd
data = {'period': [7836, 53655, 115615, 161926, 38177, 46371, 2699],
'comma': [13112, 102383, 184541, 340479, 105101, 58367, 5675],
'others': [6026, 42413, 59226, 62754, 12670, 14299, 1046]}
data = pd.DataFrame(data, columns=['period', 'comma', 'others'],
index=['Rousseau', 'Chateaubriand', 'Hugo',
'Zola', 'Proust', 'Giraudoux', 'Aloz'])| period | comma | others | |
|---|---|---|---|
| Rousseau | 7836 | 13112 | 6026 |
| Chateaubriand | 53655 | 102383 | 42413 |
| Hugo | 115615 | 184541 | 59226 |
| Zola | 161926 | 340479 | 62754 |
| Proust | 38177 | 105101 | 12670 |
| Giraudoux | 46371 | 58367 | 14299 |
| Aloz | 2699 | 5675 | 1046 |
Key Equation
Analogy
CA is PCA applied to a normalized residual table: instead of centering by subtracting the mean, it centers by subtracting the independence model , and instead of unit weighting it uses and to weight by marginal frequency — making profiles, not counts, the object of study.
Component of
Insights
- CA operates on profiles (relative frequencies), making it invariant to overall count magnitude — this is why it correctly identifies Aloz as stylistically similar to Zola.
- The generalized SVD of is the core computation; all coordinates follow from , , .
- Inertia is a chi-square-like statistic: it measures total departure from independence.
- For interpretation, prefer asymmetric maps when row-to-column distances matter; use symmetric maps when within-group distances are the focus.
Pitfalls
- Symmetric maps tempt row-to-column distance interpretation, which is not geometrically valid.
- CA assumes the association structure is low-rank; if associations are diffuse, the 2D display retains little inertia and is misleading.
- CA is for count data; applying it to continuous measurements or negative values is inappropriate.
Connections
- PCA and SVD: CA is generalized SVD applied to the standardized residual of a correspondence matrix; PCA is ordinary SVD applied to continuous data.
- Generalized SVD todo
- Chi-Square Statistic todo
Implementation Notes
# https://github.com/bowen0701/machine-learning/blob/master/correspondence_analysis.py
import numpy as np
import pandas as pd
from numpy.linalg import svd
class CorrespondenceAnalysis(object):
"""Correspondence analysis (CA).
Methods:
fit: Fit correspondence analysis.
get_coordinates: Get symmetric or asymmetric map coordinates.
score_inertia: Get score inertia.
Usage:
corranal = CorrespondenceAnalysis(aggregate_cnt)
corranal.fit()
coord_df = corranal.get_coordinates()
inertia_prop = corranal.score_inertia()
"""
def __init__(self, df):
"""Create a new Correspondence Analysis.
Args:
df: Pandas DataFrame, with row and column names.
Raises:
TypeError: Input data is not a pandas DataFrame.
ValueError: Input data contains missing values.
TypeError: Input data contains data types other than numeric.
"""
if not isinstance(df, pd.DataFrame):
raise TypeError('Input data is not a Pandas DataFrame.')
self._rows = np.array(df.index)
self._cols = np.array(df.columns)
self._np_data = np.array(df.values)
if np.isnan(self._np_data).any():
raise ValueError('Input data contains missing values.')
if not np.issubdtype(self._np_data.dtype, np.number):
raise TypeError('Input data contains data types other than numeric.')
def fit(self):
"""Compute Correspondence Analysis.
Performs generalized SVD for the correspondence matrix and
computes principal and standard coordinates for rows and columns.
Returns:
self: Object.
"""
p_corrmat = self._np_data / self._np_data.sum()
r_profile = p_corrmat.sum(axis=1).reshape(p_corrmat.shape[0], 1)
c_profile = p_corrmat.sum(axis=0).reshape(p_corrmat.shape[1], 1)
Dr_invsqrt = np.diag(np.power(r_profile, -1/2).T[0])
Dc_invsqrt = np.diag(np.power(c_profile, -1/2).T[0])
ker_mat = np.subtract(p_corrmat, np.dot(r_profile, c_profile.T))
weighted_lse = Dr_invsqrt.dot(ker_mat).dot(Dc_invsqrt)
U, sv, Vt = svd(weighted_lse, full_matrices=False)
self._Dr_invsqrt = Dr_invsqrt
self._Dc_invsqrt = Dc_invsqrt
self._U = U
self._V = Vt.T
self._SV = np.diag(sv)
self._inertia = np.power(sv, 2)
# Principal coordinates for rows and columns.
self._F = self._Dr_invsqrt.dot(self._U).dot(self._SV)
self._G = self._Dc_invsqrt.dot(self._V).dot(self._SV)
# Standard coordinates for rows and columns.
self._Phi = self._Dr_invsqrt.dot(self._U)
self._Gam = self._Dc_invsqrt.dot(self._V)
return self
def _coordinates_df(self, array_x1, array_x2):
"""Create pandas DataFrame with coordinates in rows and columns.
Args:
array_x1: numpy array, coordinates in rows.
array_x2: numpy array, coordinates in columns.
Returns:
coord_df: A Pandas DataFrame with columns
{'x_1',..., 'x_K', 'point', 'coord'}:
- x_k, k=1,...,K: K-dimensional coordinates.
- point: row and column points for labeling.
- coord: {'row', 'col'}, indicates row point or column point.
"""
row_df = pd.DataFrame(
array_x1,
columns=['x' + str(i) for i in (np.arange(array_x1.shape[1]) + 1)])
row_df['point'] = self._rows
row_df['coord'] = 'row'
col_df = pd.DataFrame(
array_x2,
columns=['x' + str(i) for i in (np.arange(array_x2.shape[1]) + 1)])
col_df['point'] = self._cols
col_df['coord'] = 'col'
coord_df = pd.concat([row_df, col_df], ignore_index=True)
return coord_df
def get_coordinates(self, option='symmetric'):
"""Take coordinates in rows and columns for symmetric or asymmetric map.
For symmetric vs. asymmetric map:
- For symmetric map, we can catch row-to-row and column-to-column
association (maybe not row-to-column association);
- For asymmetric map, we can further catch row-to-column association.
Args:
option: string, one of:
'symmetric': symmetric map with rows and columns in principal coordinates.
'rowprincipal': asymmetric map with rows in principal coordinates and
columns in standard coordinates.
'colprincipal': asymmetric map with rows in standard coordinates and
columns in principal coordinates.
Returns:
Pandas DataFrame, contains coordinates, row and column points.
Raises:
ValueError: Option only includes {"symmetric", "rowprincipal", "colprincipal"}.
"""
if option == 'symmetric':
return self._coordinates_df(self._F, self._G)
elif option == 'rowprincipal':
return self._coordinates_df(self._F, self._Gam)
elif option == 'colprincipal':
return self._coordinates_df(self._Phi, self._G)
else:
raise ValueError(
'Option only includes {"symmetric", "rowprincipal", "colprincipal"}.')
def score_inertia(self):
"""Score inertia.
Returns:
A NumPy array, contains proportions of total inertia explained
in coordinate dimensions.
"""
inertia = self._inertia
inertia_prop = (inertia / inertia.sum()).cumsum()
return inertia_propReferences
[1] Johnson & Wichern (2002). Applied Multivariate Statistical Analysis. [2] Nenadic & Greenacre (JSS, 2007). Correspondence Analysis in R, with Two- and Three-dimensional Graphics: The ca Package. [3] Greenacre (2007). Correspondence Analysis in Practice. [4] Greenacre (2010). Biplots in Practice.