A (Detailed) Peek into PCA and SVD
Outline
- What is Principal Component Analysis (PCA)?
- What is Singular Value Decomposition (SVD)?
- PCA and SVD
- References
What is PCA?
The motivation of PCA is to identify the most meaningful basis to re-express data which can maximize the signal-to-noise ratio (SNR): \(\sigma^2_{signal} / \sigma^2_{noise}\).
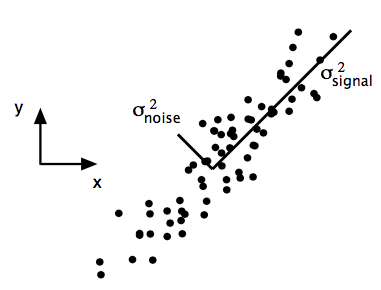
- Maximize the signal, measured by the magnitude of variance; large variance corresponds to interesting structure.
- Minimize redundancy (i.e. noise), measured by the magnitude of covariance.
Let the observed data be
\[\underset{(m \times n)}X = \{x_{ij}\} = \begin{bmatrix} x_{11} & \cdots & x_{1n} \\ \vdots & & \vdots \\ x_{m1} & \cdots & x_{mn} \end{bmatrix} = \begin{bmatrix} x^T_{1.} \\ \vdots \\ x^T_{m.} \end{bmatrix} = [x_{.1}, \cdots, x_{n}]\]where each row, \(x^T_{i.}\), represents an example measured on \(n\)-dimensional features,
\[x^T_{i.} = [x_{i1} \dots x_{in}]\]and each column, \(x_{.j}\), represents normalized feature with zero means, \(E(x_{.j}) = 0\), and variance one, \(Var(x_{.j}) = 1\).
\[x_{.j}= \begin{bmatrix} x_{1j} \\ \vdots \\ x_{mj} \end{bmatrix}\]For notation simplicity, we also denote each row \(x^T_{i.}\) by \(x^T_i\).
The covariance matrix of \(X\) is
\[\underset{(n \times n)}{\Sigma_X} = \frac{1}{m}X^{T}X = \frac{1}{m} \begin{bmatrix} x^T_{.1} \\ \vdots \\ x^T_{.n} \end{bmatrix} [x_{.1},...,x_{.n}] = \frac{1}{m} \begin{bmatrix} x^T_{.1}x_{.1} & \cdots & x^T_{.1}x_{.n} \\ \vdots & & \vdots \\ x^T_{.n}x_{.1} & \cdots & x^T_{.n}x_{.n} \end{bmatrix}\]Our goal is to find some transformation, \(Y = f(X)\), of X such that covariance of \(Y\) is a diagonal matrix,
\[\underset{(n \times n)}{\Sigma_Y} = \frac{1}{m}Y^{T}Y\]There are many transformations for diagonalizing the convariance matrix \(\Sigma_X\), PCA arguably selects the easiest one.
Assumptions for PCA
- Linear transformation: Let \(\underset{n \times n}E = [e_1,...,e_n]\),
- Large variance have important structure.
- The principal components are orthogonal.
The last assumption provides an intuitive simplification that makes PCA soluble with linear algebra decomposition techniques.
Eigendecomposition
The eigendecomposition, or eigenvector decomposition, is also called the spectral secomposition. Suppose \(Y = XE\), its covariance matrix
\[\Sigma_Y = \frac{1}{m}Y^TY = \frac{1}{m}(XE)^T(XE) = E^T \left(\frac{1}{m}X^TX \right)E\]Since \(\frac{1}{m}X^TX\) is a symmetric matrix, it can be diagonalized by a matrix of orthonormal eigenvectors using the spectral decomposistion,
\[\frac{1}{m}X^TX = VDV^T\]where \(D = diag(d_1,...,d_n)\) is a diagonal matrix with rank-ordered set of eigenvalues, \(d_1 \ge d_2 \ge ... \ge d_n\), and \(V = [v_1,...,v_n]\) is the matrix of the corresponding eigenvectors with \(V^TV=VV^T = I\).
Sketch of proof: From the spectral decomposition, for all \(j\), we have
\[\frac{1}{m}X^T X v_j = d_j v_j\]Then we have \(\frac{1}{m}X^T X V = V D\) which implies \(\frac{1}{m}X^T X = V D V^T\).
Alternative proof: We can interpret PCA as finding a unit vector \(u\), with \(\|u\| = 1\), which maximizes variance of the projection of all example \(x_i\)’s onto \(u\),
\[\frac{1}{m} \sum_{i=1}^m (x_i^T u)^2 = \frac{1}{m} \sum_{i=1}^m (x_i^T u)^T (x_i^T u) = u^T \big(\frac{1}{m} \sum_{i=1}^m x_i x_i^T \big) u\]But let’s digress a little to ask why the variance of the projection of all examples \(x_i\) onto \(u\) has form like the above? First, suppose the angle between \(x_i\) and \(u\) is \(\theta\), then the projection of each example \(x_i\) onto \(u\) is
\[x_i' = x_i cos\theta = x_i \frac{x_i^T u}{|x_i||u|} = x_i \frac{x_i^T u}{|x_i|}\]since \(u\) is a unit vector. Then the length of the projection of one example \(x_i\) onto \(u\) is
\[\left[ x_i'^T x_i' \right]^{1/2} = \left[ \left( x_i \frac{x_i^T u}{|x_i|} \right)^T \left( x_i \frac{x_i^T u}{|x_i|} \right) \right]^{1/2} = \left[ \left( \frac{x_i^T u}{|x_i|} \right) x_i^T x_i \left( \frac{x_i^T u}{|x_i|} \right) \right]^{1/2} = \left[ \left(x_i^T u \right)^2 \right]^{1/2} = x_i^T u\]since \(x_i^T x_i = \|x_i\|^2\). Finally, the projection of one example \(x_i\)’s onto \(u\) is the distance \(x_i^T u\) from the origin.
Now let’s go back to our optimization problem, we would like to solve
\[max_u u^T \big(\frac{1}{m} \sum_{i=1}^m x_i x_i^T \big) u\]such that \(u^T u = 1\). Using the lagrange multiplier method, the objective becomes
\[max_u L(u, \lambda) = u^T \big(\frac{1}{m} \sum_{i=1}^m x_i x_i^T \big) u - d (u^T u - 1)\]Take partial derivative with respect to \(u\) we have
\[\frac{\partial}{\partial u} L(u, \lambda) = \frac{1}{m} X^T X u - d u := 0\]Hence, we are solving \(\frac{1}{m} X^T X u = d u\), and the eigenvector decomposition result follows.
From the above results we can select \(E = V\). Then since \(V^TV=VV^T = I\), \(\Sigma_Y\) now is a diagonal matrix
\[\Sigma_Y = E^T \left( \frac{1}{m}X^T X \right) E = V^T \left( V D V^T \right) V = D\]Note that the eigenvalue \(d_j\) is the variance of transformed feature \(y_j\).
Summary of PCA
- Substract off the mean of each feature: \(x_j \leftarrow x_j - \overline x_j\), and divide the standard deviation: \(x_j \leftarrow x_j/\sigma_j\)
- Compute the eigenvectors of covariance matrix, \(\Sigma_X = \frac{1}{m}X^TX\)
- The ith principal components of \(X\) is the covariance matrix \(\Sigma_X\)’s eigenvector \(v_i\)
- The ith diagonal value of the transformed covariance matrix \(\Sigma_Y\) is the variance of \(X\) along \(v_i\)
What is SVD?
First recall the eigenvector decomposition: \(\frac{1}{m}X^T X v_j = d_j v_j\). Define
- Singular values: square root of eigenvalue (variance) \(\lambda_j = \sqrt{d_j}\), for \(j = 1,...,n\).
- Matrix \(U = [ u_1,...,u_n ]\), with \(u_j\) defined by
where \(v_j\) is the eigenvector.
Then we have
- (1) \(U\) is orthonormal matrix: \(u_i^T u_j = \begin{cases} 1, \text{if } i = j \\ 0, \text{otherwise} \end{cases}\)
- (2) \(\lVert X v_i\rVert = \lambda_i\)
Sketch of proof: \(u_i^T u_j = \frac{1}{m} \left( \frac{1}{\lambda_i} X v_i \right)^T \left( \frac{1}{\lambda_j} X v_j \right) = \frac{1}{\lambda_i \lambda_j} v_i^T \frac{1}{m} X^T X v_j = \frac{1}{\lambda_i \lambda_j} v_i^T d_j v_j = \frac{\lambda_j}{\lambda_i} v_i^T v_j\). The first result follows. Further, we can obtain the second result similarly.
By rewriting we have
\[\left( \frac{1}{\sqrt{m}}X \right) v_j = \lambda_j u_j\]That is, normalized \(X\) multiplied by an eigenvector \(v_j\) of covariance of \(X\), \(\frac{1}{m} X^T X\), is equal to a scalar \(\lambda_j\) times another vector, \(u_j\).
Matrix Version of SVD
- By constructing a new diagonal matrix of singular values, \(\Sigma = diag(\lambda_1,...,\lambda_n)\), where \(\lambda_1 \ge \lambda_2 \ge ... \ge \lambda_n\).
- Define \(V = [v_1,...,v_n]\) and \(U = [u_1,...,u_n]\).
Hence, any arbitrary matrix \(\frac{1}{\sqrt{m}}X\) can be transformed to
- an orthogonal matrix (rotation): \(U\)
- a diagonal matrix (stretch): \(\Sigma\)
- another orthogonal matrix (second rotation): \(V\)
PCA and SVD
From SVD, we have
\[\frac{1}{m} X^T X = \left( \frac{1}{\sqrt{m}}X \right)^T \left( \frac{1}{\sqrt{m}}X \right) = \left( U \Sigma V^T \right)^T \left( U \Sigma V^T \right) \\ = \left( V \Sigma U^T U \Sigma V^T \right) = V \Sigma^2 V^T \equiv V D V^T\]That is, squared singular value is equal to variance of \(X\) along eigenvector \(v_j\), \(\lambda_j^2 = d_j\).
How Many Pricipal Components We Shall Use?
- Total variances: \(\sum_{j=1}^n \lambda_j^2\).
- Scree plot: Choose the number of principal component by elbow method.
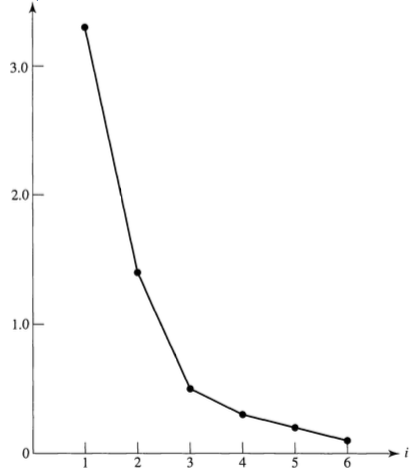
Reduced Rank Approximation by SVD
Recall from SVD,
\[\frac{1}{\sqrt{m}}X = U \Sigma V^T = \sum_{j=1}^n \lambda_j u_j v_j^T\]Let \(s < n = rank(X)\). Then the reduced rank-\(s\) least squares approximation to \(\frac{1}{\sqrt{m}} X\) is
\[\frac{1}{\sqrt{m}}\widehat{X} = \sum_{j=1}^s \lambda_j u_j v_j^T\]which minimizes the Frobenius norm,
\[\frac{1}{m} \sum_{i=1}^m \sum_{j=1}^n \left( x_{ij} - \widehat{x}_{ij} \right)^2 = tr \left[ \left(\frac{1}{\sqrt{n}} (X - \widehat{X}) \right) \left(\frac{1}{\sqrt{n}} (X - \widehat{X}) \right)^T \right]\]over all matrices \(\widehat{X}\) having rank no greater than \(s\). This optimization problem can be solved using eigendecomposition as above.
Cited as:
@article{li2016pcasvd,
title = "A (Detailed) Peek into PCA and SVD",
author = "Li, Bowen",
journal = "https://bowen0701.github.io/",
year = "2016",
url = "https://bowen0701.github.io/2016/10/05/pca-svd/"
}
If you notice errors in this post, please contact me at [bowen0701 at gmail dot com] and I would be grateful to be able to correct them.
See you in the next post. :-)
References
[1] Shlens (arXiv, 2014). A Tutorial on Principal Component Analysis.
[2] Johnson & Wichern (2002). Applied Multivariate Statistical Analysis.## References